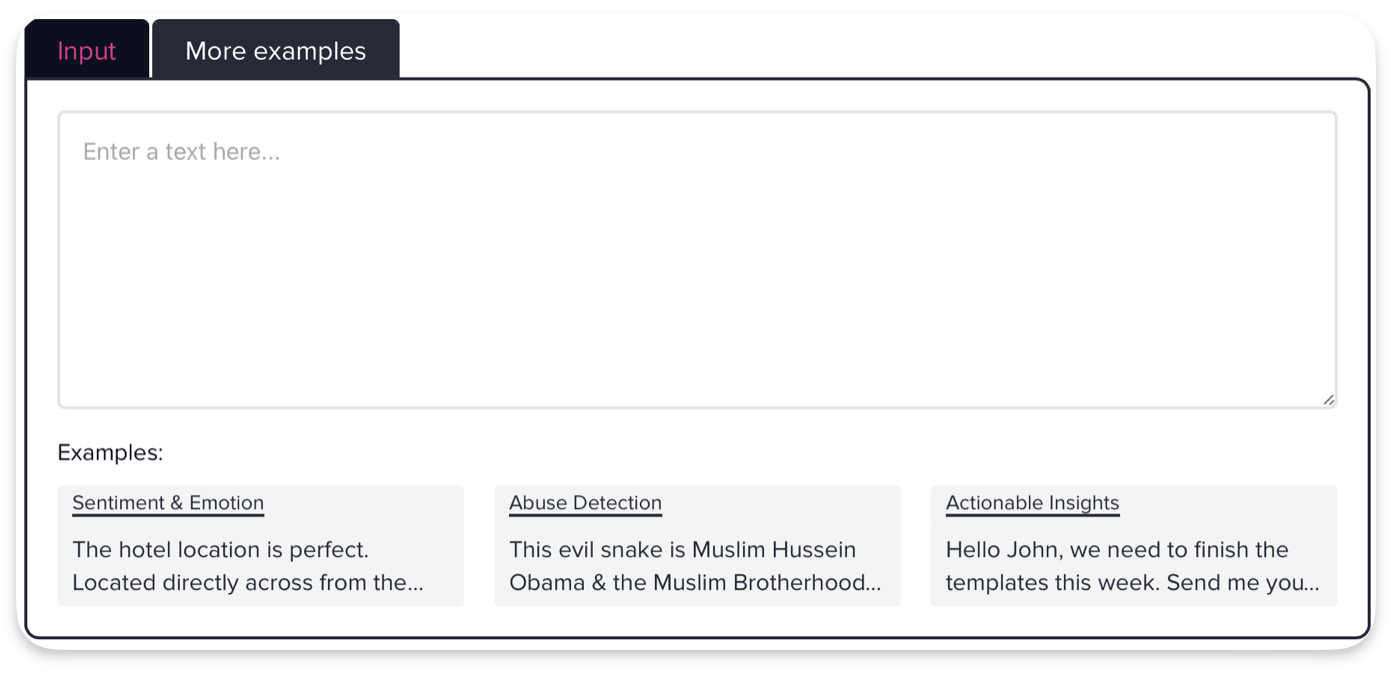
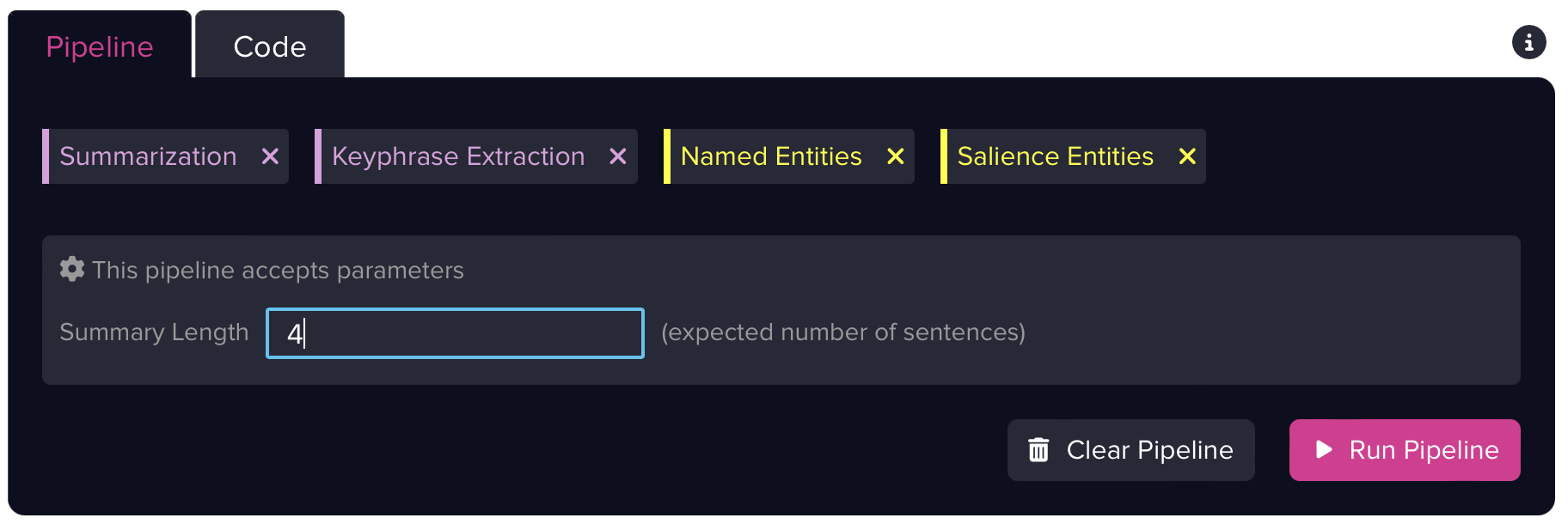
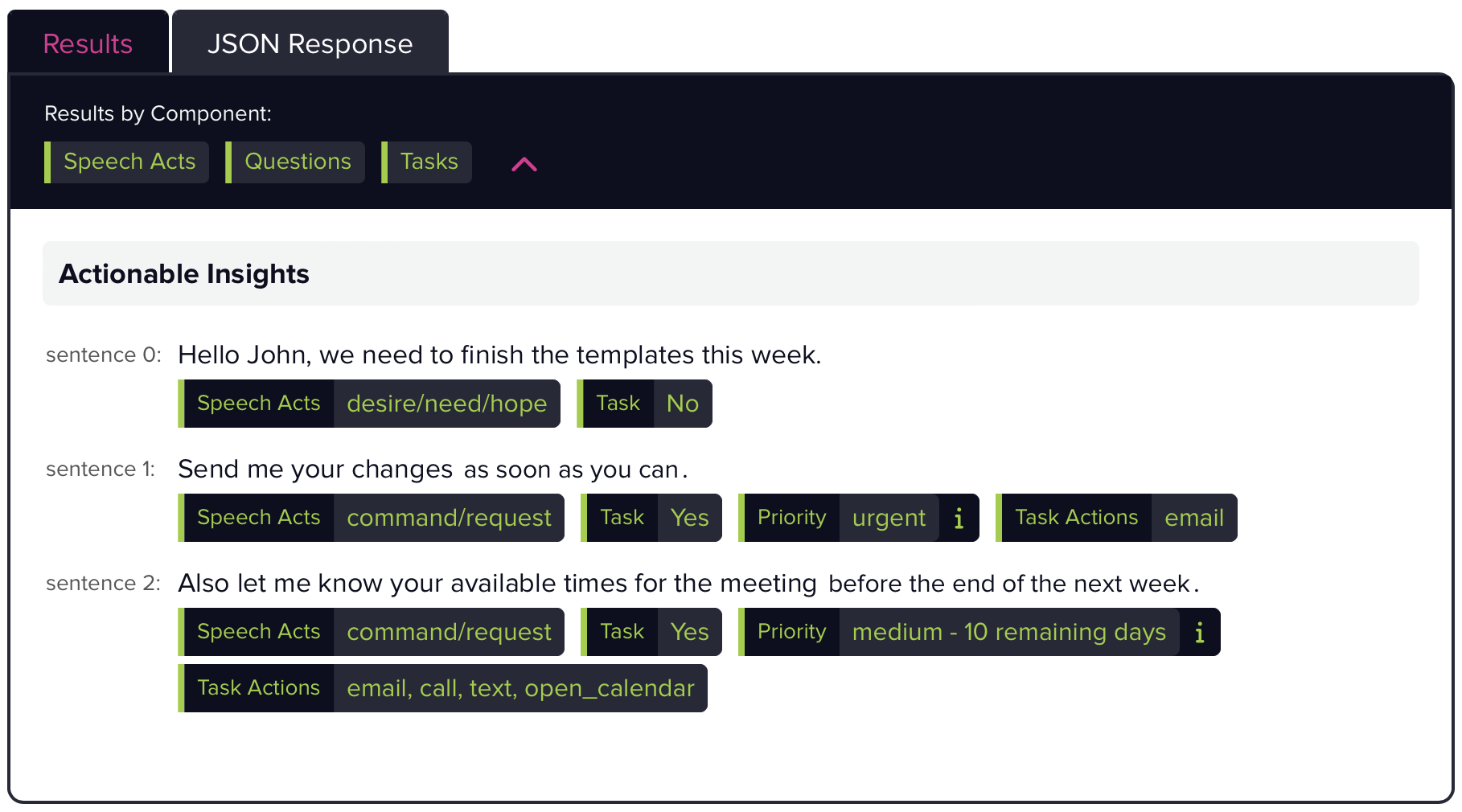
Output Labels:
statement
Conveys information from the speaker to the hearer.
command/request
Attempts to either impart an obligation on the hearer to do a certain task for the speaker or which asks the hearer to do such a task.
question
Imparts a request the hearer to give some type of information to the speaker.
desire/need/hope
Reports something that the speaker wants, needs, or hopes for, whether or not the hearer is involved or has the power to help realize this desire, need, or hope.
commitment/promise
Expresses that the speaker plans to do some stated action in the future.
evaluation
Speaker's subjective opinion about one or more people, things, events or other entities.
speculation
Speaker's uncertain belief about some event or state of affairs of the world, whether possible event/state of affairs would be in the past, present, or future.
suggestion/recommendation
Speaker's belief about the optimal course of action for some party, whether the group includes the hearer or not.
regret
The speaker would prefer that some past event or state of affairs had not occurred the way it did, whether or not the situation was caused by the speaker.
greeting
Expresses acknowledgement to the hearer, often in a conventionalized way, often in the event of the speaker and the hearer meeting, parting company, or acknowledging some recognized holiday.
permission
Expresses to the hearer that the speaker allows the hearer to perform some action, and presupposes that the speaker believes that they have the authority to grant or withhold such permission.
offer
The speaker is willing to give some object to, or do some task for, the hearer, if the hearer so desires and will accept the offer.
gratitude
The speaker is thankful for something that some party, often but not always the hearer, has done or was involved with, often in a conventionalized way.
congratulation
The speaker is proud of the hearer for some accomplishment.
disagreement
The speaker disagrees with something that the hearer has recently said.
apology/condolence
Expresses remorse for something that the speaker has done or failed to do, or which commiserates with some misfortune that the hearer has experienced.
agreement
The speaker agrees with something that the hearer has recently said.
well-wishing
The speaker hopes that the hearer will have good fortune in the future, often in a conventionalized way.
warning
Expresses that some misfortune may, or definitely will, befall some party, often the hearer but some times a third party or the speaker; sometimes the misfortune is unconditional, but sometimes the warning expresses that misfortune will occur unless someone performs or refrains from performing a certain action.
introduction
Acts to bring the hearer in acquaintance with some party, either the speaker or some third party.
unknown speech act
A sentence which cannot be classified in any of the above ways, sometimes because it cannot be interpreted; sometimes because it is in a different language than the one (English) that this classifier was built for; sometimes because it is a short interjection; etc.